

OpenAI 表示,新版ChatGPT Images由最新的旗舰级影像生成模型驱动,不论是从零开始生成图片,或是针对既有照片进行编辑,都能更贴近使用者原本的想法。此次更新的核心在于强化指令理解能力,让模型能「只改使用者指定的部分」,并在多次编修过程中,维持光线、构图与人物外貌的一致性,减少过去常见的失真问题。
以实际使用情境来看,当用户只要求更换服装、发型或整体风格时,系统会保留脸部特征与画面氛围,不会影响其他不相关元素,使修图结果更自然,也更适合应用于造型试穿、风格转换或视觉概念设计。OpenAI形容,这让ChatGPT不只是「会画图」,而是能同时兼顾实用修图与创意发想的影像工具。
在编辑能力方面,新模型也全面强化加、减、合成、混合与转换等操作,能将不同人物或物件整合进同一画面,或是逐步移除元素、转换画风,并在连续修改过程中维持整体一致性,避免画面随著调整次数增加而偏离原始设定。
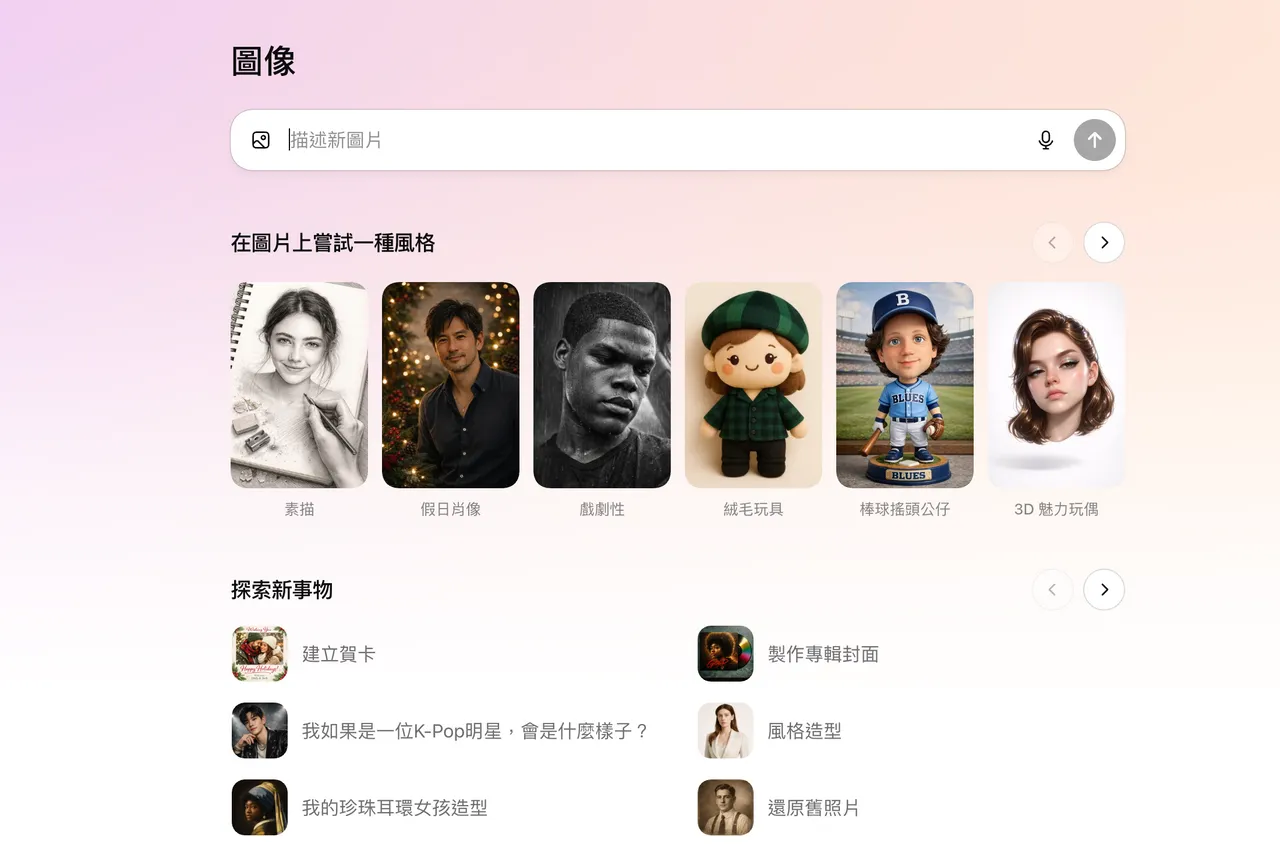
为了进一步降低使用门槛,OpenAI也同步在ChatGPT左侧介面新增专属的「图像」分类,内建多种预设风格与灵感范本。即使使用者不知道该如何撰写指令,也能直接点选范本快速开始创作,例如「建立贺卡」、「电影海报」,或是「如果我是一位 K-Pop 明星,会是什么样子」等情境式选项,ChatGPT便会自动生成对应风格的影像,并列出对应的提示指令,还能作为后续调整与延伸创作的起点。
另一项明显升级,则是文字呈现能力。新版ChatGPT Images在小字与密集文字的生成表现上更为稳定,能处理资讯图表、Markdown排版,甚至模拟报纸版面配置,对于制作简报、教学素材或社群图片的用户而言,实用性明显提升。
在开发者端,新模型也同步以GPT-Image-1.5名称开放API使用,不仅在品牌识别、构图与细节保留上更稳定,图像生成与输入成本也比前一代降低约20%。OpenAI指出,目前已有Wix、Canva、Figma、Shutterstock等平台导入相关应用,协助设计、行销与电商团队加快内容制作流程。
OpenAI也坦言,影像生成仍存在多人物一致性与跨语言细节等挑战,未来仍有进一步改善空间。不过整体而言,这次ChatGPT Images的升级,已让影像生成从过去偏向展示性质的功能,逐步走向更成熟、可实际投入工作与创作流程的工具。
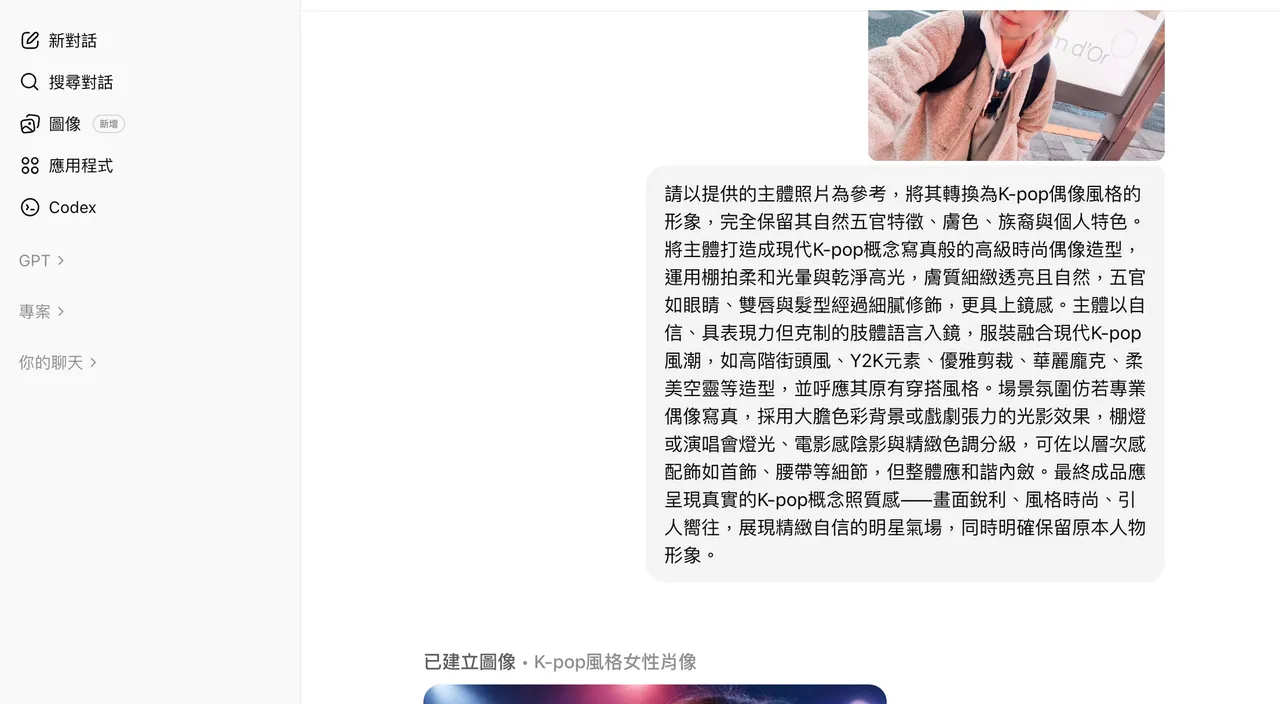
根据记者实测,操作方式也相当简单,只要在网页版的ChatGPT中选择左侧的「图像」分类后,上传照片再自行输入提示句或是参考提供的风格便会在数秒内生成图片,接著还能进一步的输入文字来做调整,在精准调整效果上的确是相当不错。
新版ChatGPT Images已于今日起陆续向所有用户开放,API也同步上线,显示生成式AI在影像领域的竞争,正持续加速推进。
🟡 ChatGPT:https://chatgpt.com/images

 點擊閱讀下一則新聞
點擊閱讀下一則新聞




